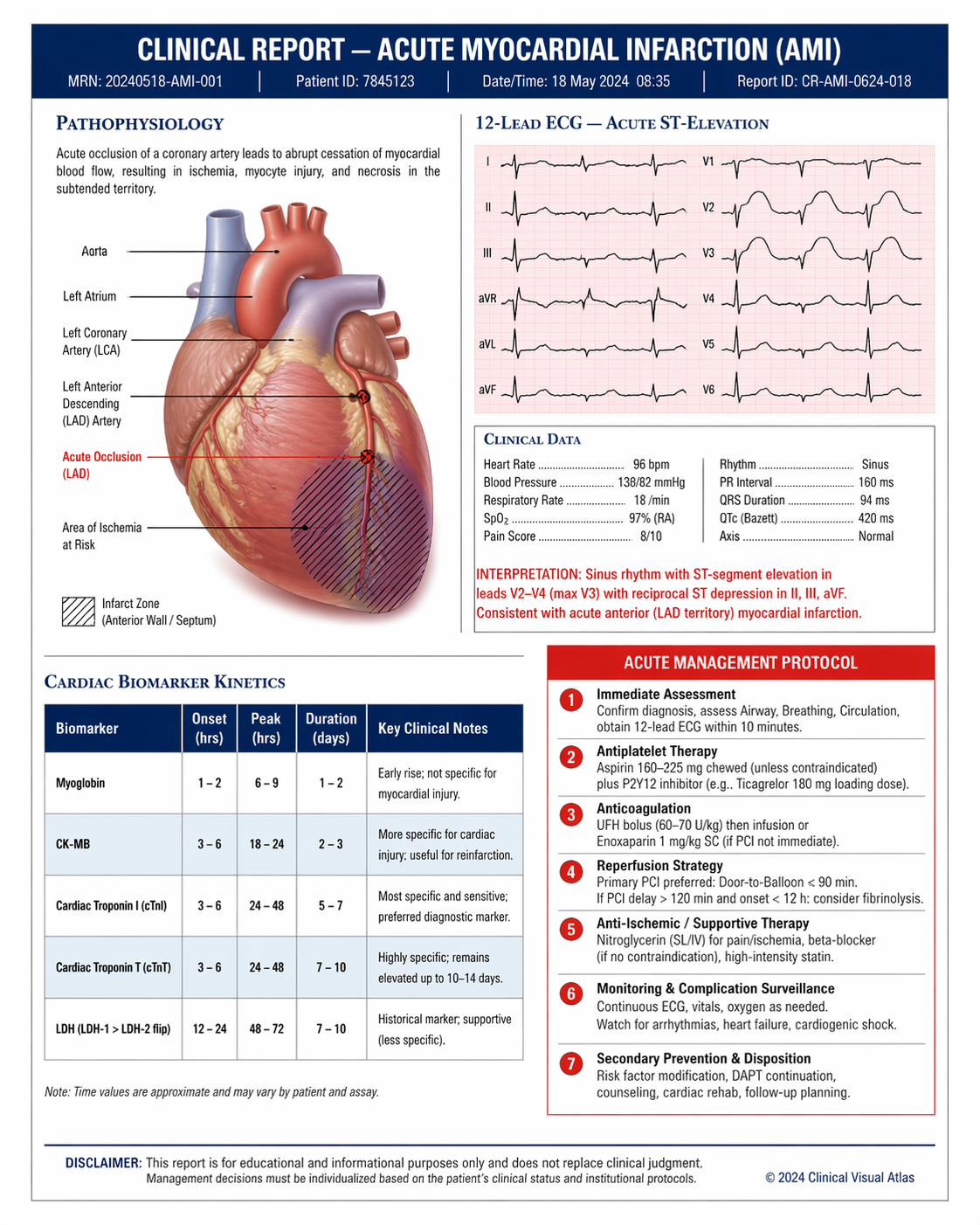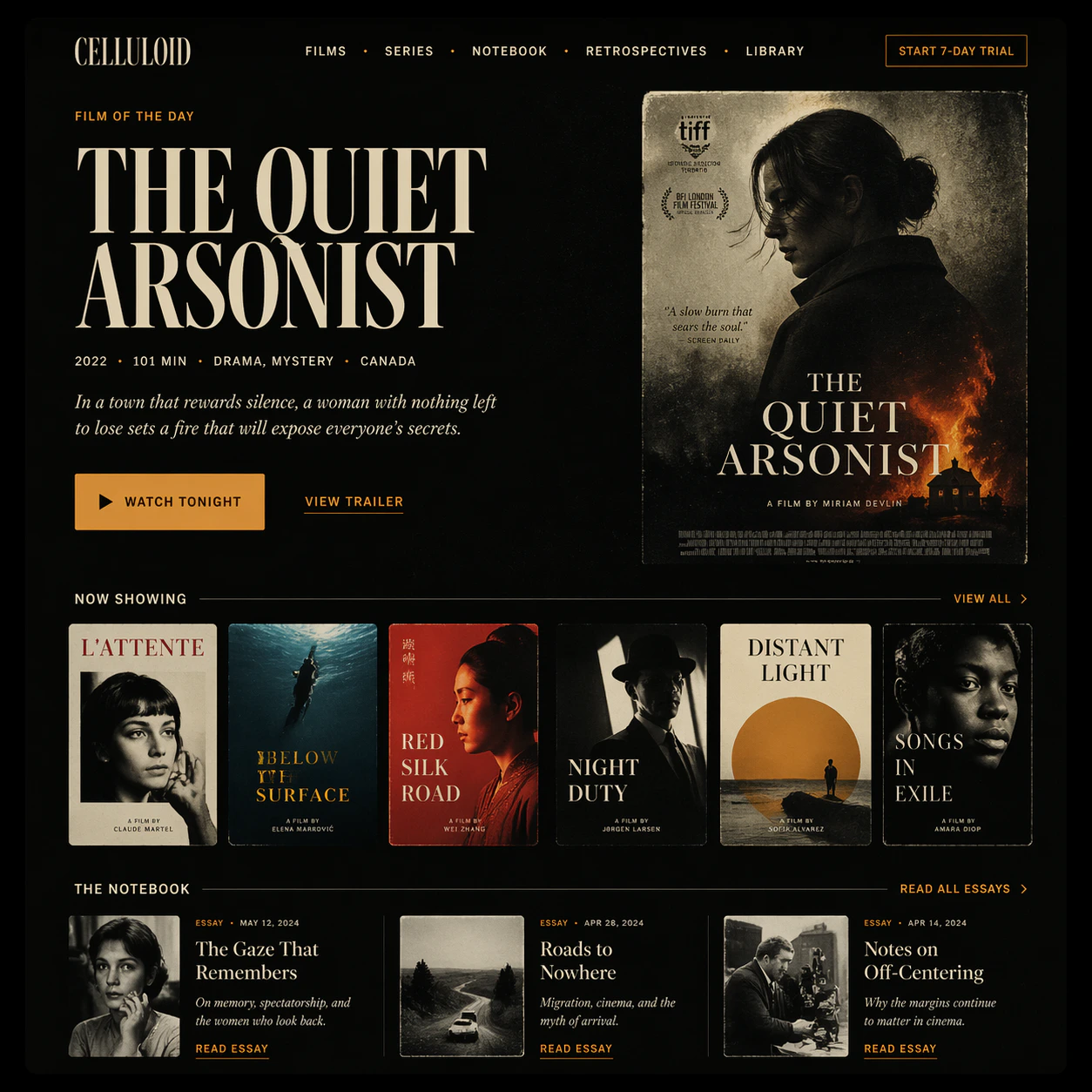
OpenAI's most advanced image model — powered by GPT-5.4. Near-perfect text rendering in any language, reasoning-driven generation, and consistent multi-image output across a single prompt. The benchmark leader for complex, knowledge-grounded, and multilingual visual work.