OpenAI's native image generation built into GPT-4o — grounded in world knowledge for accurate logos, diagrams, and text. Best-in-class for prompt-accurate, text-heavy, and multi-reference visual work.
 ## Capabilities
## Capabilities
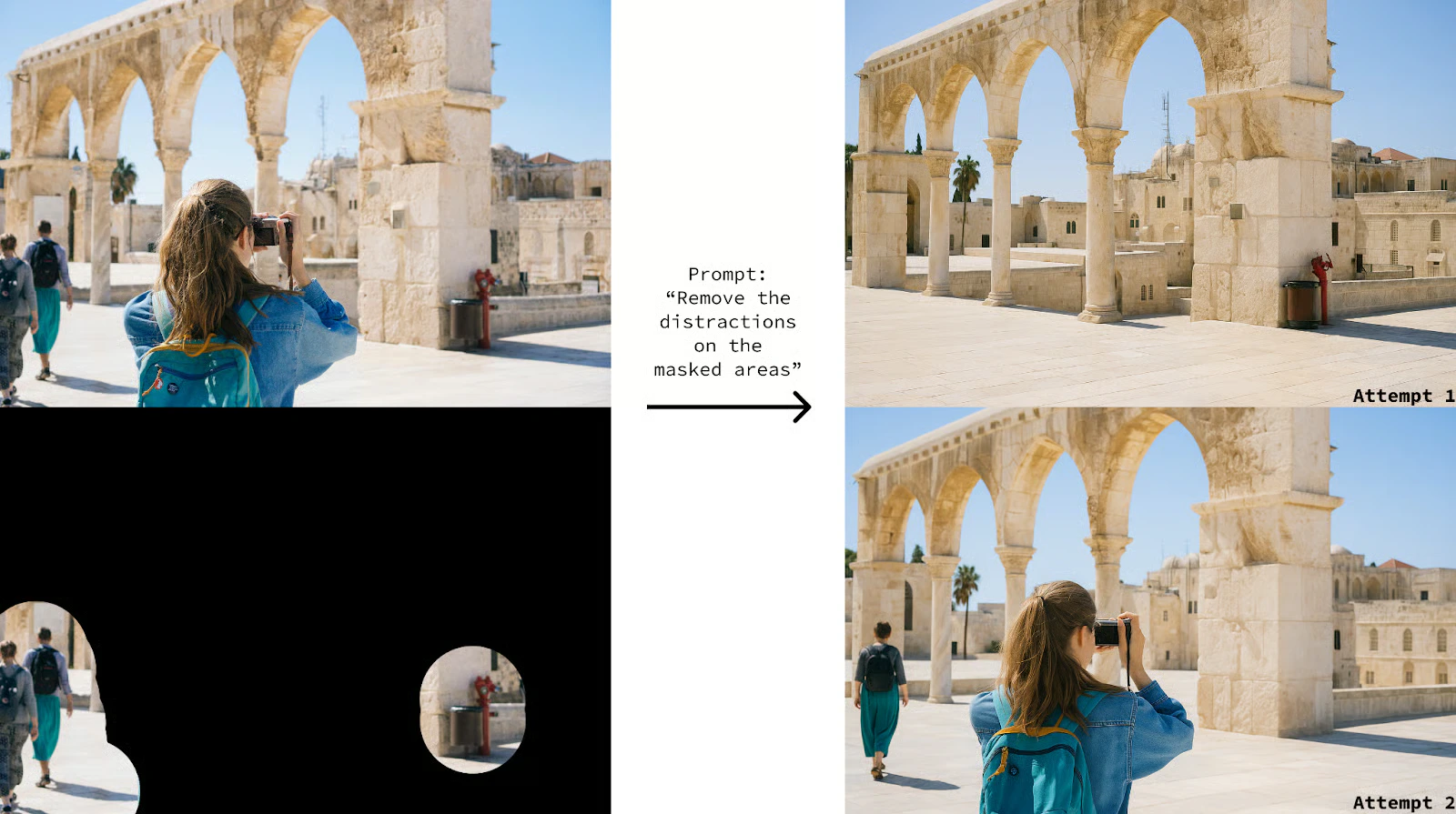 ## Specifications
| Feature | Details |
| -------------------------- | ------------------------------------------------- |
| **Model API name** | `gpt-image-1` |
| **Resolutions** | 1024×1024 (1:1), 1536×1024 (3:2), 1024×1536 (2:3) |
| **Quality tiers** | Low, Medium, High |
| **Output formats** | PNG, JPEG, WebP |
| **Transparent background** | Yes (PNG and WebP) |
| **Max reference images** | 10 (for editing workflows) |
| **Released** | March 25, 2025 |
## Specifications
| Feature | Details |
| -------------------------- | ------------------------------------------------- |
| **Model API name** | `gpt-image-1` |
| **Resolutions** | 1024×1024 (1:1), 1536×1024 (3:2), 1024×1536 (2:3) |
| **Quality tiers** | Low, Medium, High |
| **Output formats** | PNG, JPEG, WebP |
| **Transparent background** | Yes (PNG and WebP) |
| **Max reference images** | 10 (for editing workflows) |
| **Released** | March 25, 2025 |
 ## How to use
## How to use
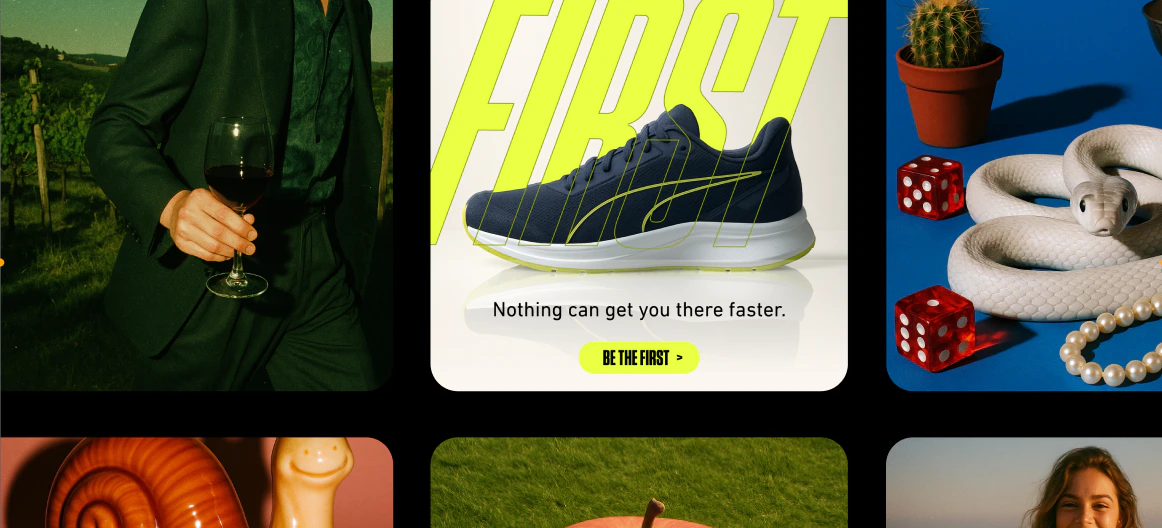 ## Prompting tips
* **Describe text content precisely** — Include exact wording, font style, and placement. Example: *"A poster with the title 'Sale Ends Friday' in large bold red sans-serif text at the top."*
* **Use it for knowledge-dependent visuals** — Prompts referencing specific brands, flags, maps, or scientific concepts will produce more accurate results than other models.
* **Multi-step editing** — Generate a base image, then use follow-up instructions to modify specific elements: *"Change the background to a sunset"*, *"Make the text white"*.
* **Be explicit with layout** — For infographics: *"Three-column layout, icons on the left, text on the right of each icon"*.
### Example prompts
> A clean infographic showing the water cycle: evaporation, condensation, precipitation, and collection. Labeled with arrows, minimal design, blue and white color palette.
> A product label for "Alpine Spring Water" with mountain imagery, clean typography, and a blue gradient background. Professional, minimal design.
> A social media post graphic for a coffee shop: warm brown tones, a latte art photo, text reading "Good Morning, Seattle" in serif font, minimal modern layout.
## Compare models
| Model | Text rendering | World knowledge | References | Best for |
| --------------------------------------------------- | --------------------- | --------------- | --------------- | ------------------------------------------------------------ |
| [ChatGPT Image 2](/ai-models/image/chatgpt-image-2) | 99%+, multilingual | Yes (GPT-5.4) | Up to 10 | Multilingual text, reasoning, 4K output |
| **ChatGPT Image** | Best-in-class | Yes (GPT-4o) | Up to 10 | Infographics, text-heavy layouts, knowledge-grounded visuals |
| **Ideogram v3** | Excellent | No | Up to 3 (style) | Typography, posters, brand design |
| **Nano Banana** | Strong | No | Up to 4 | E-commerce, product compositing |
| **Seedream 4.0** | Strong (multilingual) | No | Up to 6 | Commercial campaigns, multilingual markets |
## Prompting tips
* **Describe text content precisely** — Include exact wording, font style, and placement. Example: *"A poster with the title 'Sale Ends Friday' in large bold red sans-serif text at the top."*
* **Use it for knowledge-dependent visuals** — Prompts referencing specific brands, flags, maps, or scientific concepts will produce more accurate results than other models.
* **Multi-step editing** — Generate a base image, then use follow-up instructions to modify specific elements: *"Change the background to a sunset"*, *"Make the text white"*.
* **Be explicit with layout** — For infographics: *"Three-column layout, icons on the left, text on the right of each icon"*.
### Example prompts
> A clean infographic showing the water cycle: evaporation, condensation, precipitation, and collection. Labeled with arrows, minimal design, blue and white color palette.
> A product label for "Alpine Spring Water" with mountain imagery, clean typography, and a blue gradient background. Professional, minimal design.
> A social media post graphic for a coffee shop: warm brown tones, a latte art photo, text reading "Good Morning, Seattle" in serif font, minimal modern layout.
## Compare models
| Model | Text rendering | World knowledge | References | Best for |
| --------------------------------------------------- | --------------------- | --------------- | --------------- | ------------------------------------------------------------ |
| [ChatGPT Image 2](/ai-models/image/chatgpt-image-2) | 99%+, multilingual | Yes (GPT-5.4) | Up to 10 | Multilingual text, reasoning, 4K output |
| **ChatGPT Image** | Best-in-class | Yes (GPT-4o) | Up to 10 | Infographics, text-heavy layouts, knowledge-grounded visuals |
| **Ideogram v3** | Excellent | No | Up to 3 (style) | Typography, posters, brand design |
| **Nano Banana** | Strong | No | Up to 4 | E-commerce, product compositing |
| **Seedream 4.0** | Strong (multilingual) | No | Up to 6 | Commercial campaigns, multilingual markets |